Data Load
from google.colab import drive
drive.mount('/gdrive')Mounted at /gdriveimport pandas as pd
import numpy as np
from sklearn.metrics import silhouette_score as sil
from sklearn.cluster import KMeans
import seaborn as sns
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt| Unnamed: 0 | company | code | esg | e | s | g | AV | ret | sector | sector_class | AV_log | ret_group | sector_num | sector_count | sector_2 | sector_3 | sector_4 | sector_5 | sector_6 | sector_7 | sector_8 | sector_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | BNK금융지주 | 138930 | 6 | 4 | 6 | 6 | 1.851312e+12 | -0.000826 | 기타 금융업 | 금융 및 보험업 | 28.246916 | 1 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | DGB금융지주 | 139130 | 6 | 5 | 6 | 6 | 1.148500e+12 | 0.000187 | 기타 금융업 | 금융 및 보험업 | 27.769478 | 2 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | JB금융지주 | 175330 | 6 | 5 | 5 | 6 | 1.110984e+12 | 0.000460 | 기타 금융업 | 금융 및 보험업 | 27.736267 | 2 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | KB금융 | 105560 | 6 | 6 | 6 | 6 | 1.804606e+13 | 0.000152 | 기타 금융업 | 금융 및 보험업 | 30.523949 | 2 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | S-Oil | 10950 | 6 | 5 | 6 | 6 | 7.790729e+12 | -0.000677 | 석유 정제품 제조업 | 제조업 | 29.683956 | 1 | 9 | 314 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Sector의 경우, 섹터의 번호는 수치적인 의미를 갖는 것을 방지하기 위해 각 Sector에 대한 더미변수를 생성하여 총 9개의 column으로 구분하였다.
또한, ESG의 등급 score이 1~6으로 지정될 경우, A+이 D에 비해 6배 높게 수치화되어 왜곡된 결과를 불러올 수 있기 때문에 검토가 필요하였다. 따라서 박은진, <ESG전략이 기업의 재무 성과에 미치는 영향(2018)>, KAIST 논문을 참고하여 score를 재부여하였다.
grade_mapper = {6 : 120, 5 : 110, 4 : 100, 3 : 90, 2 : 80, 1 : 70}
esg['e'] = esg['e'].map(grade_mapper)
esg['s'] = esg['s'].map(grade_mapper)
esg['g'] = esg['g'].map(grade_mapper)
esg['esg'] = esg['esg'].map(grade_mapper)
esg.head()| Unnamed: 0 | company | code | esg | e | s | g | AV | ret | sector | sector_class | AV_log | ret_group | sector_num | sector_count | sector_2 | sector_3 | sector_4 | sector_5 | sector_6 | sector_7 | sector_8 | sector_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | BNK금융지주 | 138930 | 120 | 100 | 120 | 120 | 1.851312e+12 | -0.000826 | 기타 금융업 | 금융 및 보험업 | 28.246916 | 1 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | DGB금융지주 | 139130 | 120 | 110 | 120 | 120 | 1.148500e+12 | 0.000187 | 기타 금융업 | 금융 및 보험업 | 27.769478 | 2 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | JB금융지주 | 175330 | 120 | 110 | 110 | 120 | 1.110984e+12 | 0.000460 | 기타 금융업 | 금융 및 보험업 | 27.736267 | 2 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | KB금융 | 105560 | 120 | 120 | 120 | 120 | 1.804606e+13 | 0.000152 | 기타 금융업 | 금융 및 보험업 | 30.523949 | 2 | 2 | 83 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | S-Oil | 10950 | 120 | 110 | 120 | 120 | 7.790729e+12 | -0.000677 | 석유 정제품 제조업 | 제조업 | 29.683956 | 1 | 9 | 314 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Model 1
Sector, 시가총액, e, s, g 포함 Clustering
Prep
먼저 Elbow Score를 구한다. 아래의 그래프에서 가장 급격하게 기울기가 변경되는 지점은 3이므로 클러스터의 개수를 3으로 설정하였다.
all_scores1 = []
features1 = ['e', 's', 'g', 'AV_log', 'sector_2', 'sector_3', 'sector_4', 'sector_5',
'sector_6', 'sector_7', 'sector_8', 'sector_9']
for i in range(10):
i = i + 2
model1 = KMeans(n_clusters=i)
model1.fit(esg[features1])
sil_score = sil(esg[features1], model1.labels_)
# 새로운 모델 만들 때마다 fit(학습) 하고 실루엣 방식으로 점수를 뽑아냄
elbow_score = model1.inertia_
score_dict = {'cluster_num' : i, 'sil_score' : sil_score, 'elbow' : elbow_score}
all_scores1.append(score_dict)
score_df1 = pd.DataFrame(all_scores1)
sns.lineplot(data=score_df1, x='cluster_num', y='elbow')
# 적정 cluster_num = 3<matplotlib.axes._subplots.AxesSubplot at 0x7f19ae98ec50>
# Scaling
from sklearn.preprocessing import StandardScaler
esg_revise = esg[features1]
scaler = StandardScaler()
scaler.fit(esg_revise.values)
esg_scaled = scaler.transform(esg_revise.values)
esg_scaled1 = pd.DataFrame(esg_scaled)
esg_scaled1.columns = features1
esg_scaled1.head()| e | s | g | AV_log | sector_2 | sector_3 | sector_4 | sector_5 | sector_6 | sector_7 | sector_8 | sector_9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.876859 | 1.867814 | 2.663795 | 0.775274 | 2.394773 | -0.104163 | -0.281337 | -0.207148 | -0.306486 | -0.192629 | -0.182405 | -1.115787 |
| 1 | 1.641545 | 1.867814 | 2.663795 | 0.465823 | 2.394773 | -0.104163 | -0.281337 | -0.207148 | -0.306486 | -0.192629 | -0.182405 | -1.115787 |
| 2 | 1.641545 | 0.981474 | 2.663795 | 0.444297 | 2.394773 | -0.104163 | -0.281337 | -0.207148 | -0.306486 | -0.192629 | -0.182405 | -1.115787 |
| 3 | 2.406232 | 1.867814 | 2.663795 | 2.251129 | 2.394773 | -0.104163 | -0.281337 | -0.207148 | -0.306486 | -0.192629 | -0.182405 | -1.115787 |
| 4 | 1.641545 | 1.867814 | 2.663795 | 1.706689 | -0.417576 | -0.104163 | -0.281337 | -0.207148 | -0.306486 | -0.192629 | -0.182405 | 0.896229 |
- Scale을 통일하기 위해 StandardScaler 적용
model1 = KMeans(n_clusters = 3)
model1.fit(esg_scaled1)
esg_scaled1['cluster'] = model1.labels_ k- Statistics of each Cluster
esg_scaled1['ret'] = esg['ret']
esg_scaled1['sector_class'] = esg['sector_class']
cluster_df = esg_scaled1.groupby('cluster').agg({'e' : np.mean, 's' : np.mean, 'g' : np.mean, 'AV_log' : np.mean})
cluster_0 = esg_scaled1.loc[esg_scaled1['cluster'] == 0]
cluster_1 = esg_scaled1.loc[esg_scaled1['cluster'] == 1]
cluster_2 = esg_scaled1.loc[esg_scaled1['cluster'] == 2]
cluster_df['ret'] = [cluster_0['ret'].mean(), cluster_1['ret'].mean(), cluster_2['ret'].mean()]
cluster_df['ret_sd'] = [cluster_0['ret'].std(), cluster_1['ret'].std(), cluster_2['ret'].std()]
cluster_df.sort_values(by = 'ret', ascending = False)| e | s | g | AV_log | ret | ret_sd | |
|---|---|---|---|---|---|---|
| cluster | ||||||
| 1 | -0.078999 | -0.532689 | -0.460467 | -0.469280 | 0.001446 | 0.001764 |
| 2 | 1.139037 | 1.215721 | 1.096823 | 1.056544 | 0.001122 | 0.001650 |
| 0 | -0.894254 | -0.190781 | -0.206399 | -0.155007 | 0.000975 | 0.001550 |
Cluster 2의 e, s, g, 시가총액이 가장 크지만 ret 값은 가장 높지 않다.
변수 개수가 많은 관계로 다차원 변수들을 2차원으로 축소하여 시각화하기 위해 TSNE 알고리즘을 활용하였다. 시각화를 해본 결과, 클러스터가 중구난방으로 퍼져 있고 일정하게 모여 있지 않은 모습이다. 따라서 이 모델을 구성하는 변수들 중 수정 및 제거해야 하는 변수가 포함되어 있다고 예측하였다.
feature_df1 = pd.DataFrame(esg_scaled1[features1])
transformed1 = TSNE(n_components=2).fit_transform(feature_df1)
xs = transformed1[:,0]
ys = transformed1[:,1]
plt.scatter(xs,ys, c=esg_scaled1['cluster']) #라벨은 색상으로 분류됨
plt.show()
Result
fig, ax = plt.subplots(nrows=3, figsize = (7, 10))
x1 = 'e'
x2 = 's'
x3 = 'g'
y = 'sector_class'
hue = 'cluster'
scatter_df1 = esg_scaled1.groupby([y, hue]).agg({x1 : np.mean}).reset_index()
scatter_df2 = esg_scaled1.groupby([y, hue]).agg({x2 : np.mean}).reset_index()
scatter_df3 = esg_scaled1.groupby([y, hue]).agg({x3 : np.mean}).reset_index()
sns.scatterplot(data = scatter_df1, x = x1, y = y, hue = hue, ax = ax[0])
sns.scatterplot(data = scatter_df2, x = x2, y = y, hue = hue, ax = ax[1])
sns.scatterplot(data = scatter_df3, x = x3, y = y, hue = hue, ax = ax[2])
- 3개의 seaborn 그래프를 통해 알 수 있는 것
- sector를 기준으로 그래프를 나누었을 때에는 큰 관련성을 찾을 수 없다,
- e, s, g(x축들)을 기준으로 그래프를 나누면 같은 색깔(cluster)끼리 모여있는 경향성이 있다.
- 이 경향성은 e에서 더욱 두드러진다.
- Sector보다 e, s, g에 의해 cluster이 나누어지는 경향이 강하다.
- 따라서, Model2에서는 Sector 더미변수들을 제외하고 Clustering 시도하였다.
Model 2
Sector 제외 Clustering
Prep
all_scores = []
features2 = ['e', 's', 'g', 'AV_log']
for i in range(10):
i = i + 2
model2 = KMeans(n_clusters=i)
model2.fit(esg[features2])
sil_score = sil(esg[features2], model2.labels_)
elbow_score = model2.inertia_
score_dict = {'cluster_num' : i, 'sil_score' : sil_score, 'elbow' : elbow_score}
all_scores.append(score_dict)
score_df = pd.DataFrame(all_scores)
sns.lineplot(data=score_df, x='cluster_num', y='elbow')
# 적정 cluster_num = 3 or 4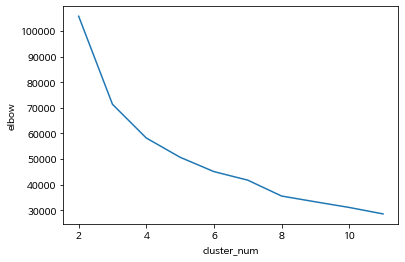
esg_scaled2 = pd.DataFrame(esg_scaled)
esg_scaled2.columns = features2
esg_scaled2['ret'] = esg['ret']
esg_scaled2['sector_class'] = esg['sector_class']
model2 = KMeans(n_clusters = 3)
model2.fit(esg_scaled2[features2])
esg_scaled2['cluster'] = model2.labels_
cluster_df = esg_scaled2.groupby('cluster').agg({'e' : np.mean, 's' : np.mean, 'g' : np.mean, 'AV_log' : np.mean})
cluster_0 = esg_scaled2.loc[esg_scaled2['cluster'] == 0]
cluster_1 = esg_scaled2.loc[esg_scaled2['cluster'] == 1]
cluster_2 = esg_scaled2.loc[esg_scaled2['cluster'] == 2]
cluster_df['ret'] = [cluster_0['ret'].mean(), cluster_1['ret'].mean(), cluster_2['ret'].mean()]
cluster_df['ret_sd'] = [cluster_0['ret'].std(), cluster_1['ret'].std(), cluster_2['ret'].std()]
cluster_df.sort_values(by = 'ret', ascending = False)| e | s | g | AV_log | ret | ret_sd | |
|---|---|---|---|---|---|---|
| cluster | ||||||
| 0 | 0.203935 | -0.649390 | -0.688125 | -0.645514 | 0.001424 | 0.001768 |
| 2 | -1.031072 | -0.260279 | -0.072491 | -0.159439 | 0.001175 | 0.001644 |
| 1 | 1.066813 | 1.162130 | 0.969861 | 1.027448 | 0.001070 | 0.001629 |
- Model 1과 비슷하게 ESG 등급이 가장 높은 특정 클러스터가 시가총액도 가장 높게 나타난다. 그리고, ret 값은 가장 낮게 나타났다.
- Cluster 별로 ret 값의 차이의 간격이 크지 않기 때문에 유의미한 차이는 아닐 것이라고 예측할 수 있다.
feature_df2 = pd.DataFrame(esg_scaled2[features2])
transformed2 = TSNE(n_components=2).fit_transform(feature_df2)
xs = transformed2[:,0]
ys = transformed2[:,1]
plt.scatter(xs,ys, c=esg_scaled2['cluster']) #라벨은 색상으로 분류됨
plt.show()TSNE로 차원축소를 해본 결과, 첫 번째 모델보다는 비교적 같은 Cluster끼리 모여 있는 모습이다.
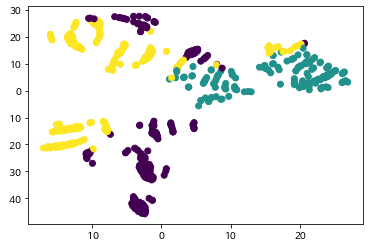
Result
plt.scatter(esg_scaled2['AV_log'], esg_scaled2['ret'], c=esg_scaled2['cluster'])
plt.title('AV - Return (by Cluster)')
plt.xlabel("AV_log")
plt.ylabel("Return")Text(0, 0.5, 'Return')
/usr/local/lib/python3.7/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 8722 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.7/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 8722 missing from current font.
font.set_text(s, 0, flags=flags)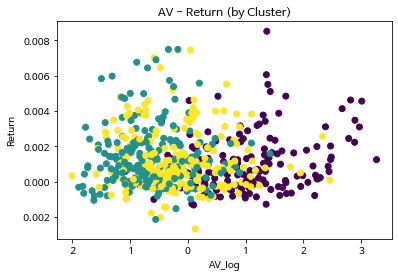
- Return 값에 따라 Cluster이 분류되는 정도는 매우 낮다.
- 즉, 앞선 ret 값의 mean 차이는 매우 미미하며 영향력이 거의 없다고 봐도 무방하다.
- 전체적으로는 시가총액과 ret 값이 우상향하는 관계는 아니지만, 특정 몇몇 구간에서는 시가총액에 따라 ret 값이 상승하는 양상을 어느 정도 확인 가능하다.
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(15,5))
fig.suptitle('E, S, G - Return (by Cluster)')
ax1.scatter(esg_scaled2['e'], esg_scaled2['ret'], c=esg_scaled2['cluster'])
ax1.set_xlabel('E')
ax1.set_ylabel('Return')
ax2.scatter(esg_scaled2['s'], esg_scaled2['ret'], c=esg_scaled2['cluster'])
ax2.set_xlabel('S')
ax3.scatter(esg_scaled2['g'], esg_scaled2['ret'], c=esg_scaled2['cluster'])
ax3.set_xlabel('G')
- S, G 보다 E에 의해 Cluster이 분류되는 정도가 더 강하게 나타난다.
- S, G를 x축으로 설정한 그래프에서는 초록색, 노란색 Cluster이 중간 중간 많이 섞여 있다.
- E, G를 x축으로 설정한 그래프의 경우, 등급이 최고점인 경우 오히려 ret 값이 낮게 나타나는 경향이 있다.
- E가 가장 낮은 그룹이 S, G에서는 중간 등급 그룹에 속한다. (roughly)
Conclusion
- 섹터 변수는 ESG와 시가총액이 수익률에 미치는 영향과는 큰 관련성이 없다.
- 2020년 기준으로는 ESG 등급이 높은 그룹이 수익률이 특별히 높게 나타나지 않았다.
- 다만, ESG 등급이 높은 그룹은 시가총액이 높은 기업들이 주로 포함된 그룹이었기 때문에, 기업의 수익률이 ESG보다는 시가총액에 의해 결정될 확률이 높을 것 같다고 판단하였다.
- 한국기업지배구조원에서 원점수로 연구했던 기존 연구결과에서는 E를 제외한 S, G, ESG통합점수가 토빈q 같은 기업가치 지표에 유의미한 영향을 준다는 내용을 발표하였었는데, 해당 연구결과에서 나타내는 기업가치들이 수익률에 아직은 반영되지 않았다는 결론을 내릴 수 있다.
한계점 & 보완점
- 수익률 데이터 수집 기간이 1년으로 한정되었으므로, ESG에 대한 평가 요소가 수익률에 반영되는 데 시간이 소요될 수 있다는 점을 고려한다면, 오차가 발생하였을 수 있다.
- 2020년 코로나 이슈로 인해 수익률 데이터의 변동성이 기존과는 다른 양상을 보일 수 있다. 즉, 앞으로 2025년까지의 데이터 수집 후 더욱 안정적인 분석이 가능할 것으로 예측된다.
- 확보할 수 있는 ESG 평가 등급 자료가 한국기업지배구조원으로 한정되었다. 다른 기관들의 등급을 함께 활용한다면 더욱 다각적인 분석이 가능할 것이다.
- E, S, G 의 지표를 단순히 등급으로 서열화하기 보다 각 부문에 대한 원점수를 공개한다면 정확성이 높아질 것으로 기대할 수 있다.
'Python Programming > Projects' 카테고리의 다른 글
| Automation System for Crawling Information from Sustainalytics (0) | 2021.08.03 |
|---|---|
| WebPage Content Crawling & Preprocessing (0) | 2021.08.03 |
| 기업의 ESG 요소와 수익률 간의 상관관계 분석(1) - Data Prep & Exploration (0) | 2021.06.02 |
| 국가 및 연도 별 총생산량(GDP)과 1인당 GDP에 대한 비교분석(2) - 시각화와 결과 (1) | 2021.02.18 |
| COVID19 - Consumption Pattern Change in Itaewon (0) | 2021.02.14 |



